

안녕하세요🐶
빈지식 채우기의 비니🙋🏻♂️ 입니다.
오늘은 RAG 에 필요한 구성요소들을 조합하여 실제로 RAG 개발을 해보는 시간을 가지도록 하겠습니다.
바로 가시죠!
1. 개요
RAG 아키텍쳐는 아래와 같이 설계하였습니다.
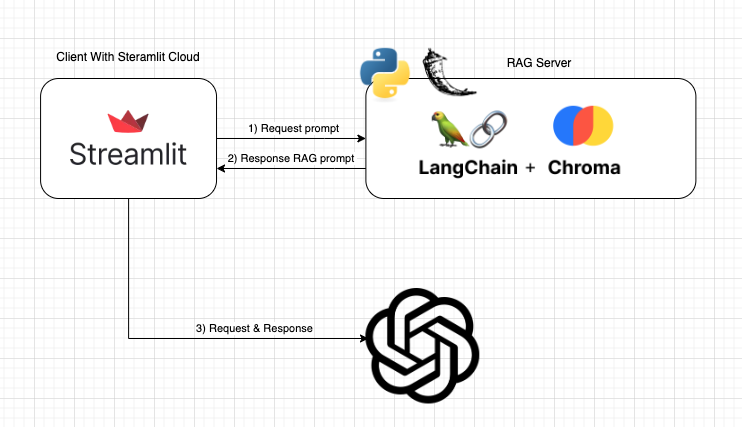
- Anaconda : Python 가상환경 구성
- Streamlit(UI) : 데이터 분석과 시각화를 함께 간편하게 수행 가능한 파이썬 오픈소스 라이브러리
- RAG Server
- LangChain : 언어 모델을 기반으로 한 어플리케이션을 개발하기 위한 프레임워크
- Chroma : 임베딩 벡터를 저장하기 위한 오픈소스 소프트웨어 ( Vector DB )
- Hugging Face : 다양한 트렌스포머 모델과 학습 스크립트를 제공하는 모듈 ( 임베딩 )
- OpenAI : 사용자의 프롬프트를 분석하여 원하는 정보를 제공하는 AI 소프트웨어
2. 아나콘다 ( Anaconda ) 가상환경
개발에 사용된 언어는 Python 입니다.
독립적인 개발 환경 구축을 위해 아나콘다(Anaconda) 가상환경을 사용하여 개발을 시작하였습니다.
Download Now | Anaconda
Anaconda is the birthplace of Python data science. We are a movement of data scientists, data-driven enterprises, and open source communities.
www.anaconda.com

자신의 사양에 맞는 설치 파일을 다운로드 후 순서에 맞게 진행합니다.
# 버전 확인
conda --version
// conda 24.5.0- 터미널에서 잘 설치가 되었는지 확인합니다.
# 새 가상환경 만들기
conda create --name "가상환경이름" python="파이썬버젼"
// conda create --name rag_test python=3.4- 가상환경 구축을 진행합니다.
- python = 를 사용하여 특정 버전의 가상환경 생성도 가능합니다.
# 가상환경 활성화
conda activate "가상환경이름"
// conda activate rag_test
# 가상환겅 비활성화
conda deactivate- 생성한 가상환경을 실행합니다.
# 가상환경 삭제하기
conda remove --name "가상환경이름"
// conda remove --name rag_test- 가상환경 삭제는 위와 같이 진행합니다.
3. 필수 구성요소 설치
필수 구성요소를 pip 를 통해 설치합니다.
# 가상환경 실행
conda activate rag_test
# 구성요소 설치
pip install langchain
pip install streamlit
pip install openai
pip install langchain_community
pip install PyPDF2
pip install flask
pip install chromadb4. 구현
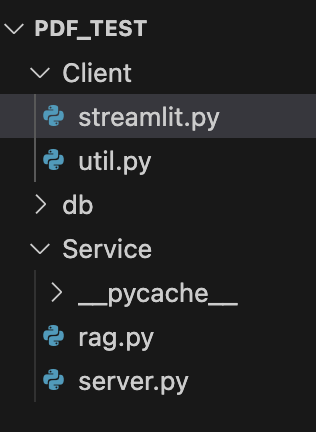
- Client
- streamlit.py : 화면 UI 랜더링 로직이 포함되어 있습니다.
- util.py : PDF 리더 및 API 통신 로직이 포함되어 있습니다.
- db : Vector DB ( Chroma ) 저장소 및 정보가 포함되어 있습니다.
- Service
- rag.py : RAG 기능을 수행하는 로직이 포함되어 있습니다.
- server.py : Flask API 로직이 포함되어 있습니다.
4.1 Streamlit.py
import util
import streamlit as st
# 파일 업로드 UI
user_upload = st.file_uploader("파일을 업로드해주세요~", accept_multiple_files=False)
if user_upload is not None:
if st.button("Upload"):
with st.spinner("PDF 처리중.."):
# PDF 텍스트 가져오기
raw_text = util.get_pdf_text(user_upload)
util.send_api(raw_text, "pdf")- Streamlit 에서 제공하는 선택한 파일에 대한 정보를 가지고 오는 로직입니다.
- 선택된 PDF 파일을 text 로 변환합니다.
- 변환된 text 를 Flask API 통신을 통해 청크 데이터로 전달합니다.
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "안녕하세요. Bot 입니다. 무엇을 도와드릴까요?"}]
# 대화형 UI 로직
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])- 첫 진입 시 보여주는 봇의 말머리 문구를 설정합니다.
- 대화형 UI로 설계가 되었기 때문에 이전 대화를 불러와 화면에 표시합니다.
if user_query := st.chat_input("질문을 입력해주세요~"):
st.session_state.messages.append({"role": "user", "content": user_query})
st.chat_message("user").write(user_query)
with st.spinner("답변 처리중.."):
# 대화 체인을 사용하여 사용자의 메시지를 처리
response = util.send_api(user_query, "handbook")
result = response.json()
st.session_state.messages.append({"role": "assistant", "content": result["message"]})
st.chat_message("assistant").write(result["message"])- Streamlit 에서 제공하는 채팅창 UI 를 넣습니다.
- 사용자가 입력한 채팅(질문-프롬프트) 를 Flask API 통신을 통해 결과값을 받아 화면에 뿌려줍니다.
4.2 Util.py
from PyPDF2 import PdfReader
import requests
import json
#PDF 문서에서 텍스트를 추출
def get_pdf_text(pdf):
text = ""
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text- PDF 에서 Text 를 추출하는 로직입니다.
#Flask API 통신
def send_api(data, path):
API_HOST = "http://127.0.0.1:80/"
url = API_HOST + "/" + path
headers = {'Content-Type': 'application/json', 'charset': 'UTF-8', 'Accept': '*/*'}
body = {
"data": data
}
try:
response = requests.post(url, headers=headers, data=json.dumps(body))
print(response.json())
return response
except Exception as ex:
print(ex)- Flask API 통신을 하는 로직입니다.
- Post 통신으로 이루어집니다.
4.3 rag.py
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain, RetrievalQA
from langchain.memory import ConversationBufferWindowMemory
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
api_key="sk-xxxxx"
#지정된 조건에 따라 주어진 텍스트를 더 작은 덩어리로 분할
def get_text_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(
separators = "\\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len
)
chunks = text_splitter.split_text(text)
return chunks- 텍스트를 통해 청크를 만드는 로직입니다.
- 청크 사이즈 및 오버랩 등 사용자가 원하는 크기로 청크를 생성합니다.
#주어진 텍스트 청크에 대한 임베딩을 생성하고 Chroma를 사용하여 벡터 저장소를 생성
def get_vectorstore(text_chunks):
#Hugging Face를 사용한 임베딩
hf = HuggingFaceEmbeddings(
model_name='jhgan/ko-sroberta-nli',
model_kwargs={'device':'cpu'},
encode_kwargs={'normalize_embeddings':False},
)
#Vector DB 생성
VectorDB = Chroma.from_texts(text_chunks,
hf,
collection_name = "handbook",
persist_directory = "./db/chromadb"
)
return VectorDB- Chroma ( Vector DB ) 를 생성하는 로직입니다.
- 청크로 변환된 텍스트를 Chroma 에 넣고 생성합니다.
- Hugging Face 임베딩을 통해 청크 데이터를 벡터로 변환시킵니다.
#주어진 벡터 저장소로 대화 체인을 초기화
def get_conversation_chain(vectorstore):
memory = ConversationBufferWindowMemory(memory_key='chat_history', return_message=True) #ConversationBufferWindowMemory에 이전 대화 저장
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0, model_name='gpt-4o', api_key=api_key),
retriever=vectorstore.as_retriever(),
get_chat_history=lambda h: h,
memory=memory
) #ConversationalRetrievalChain을 통해 langchain 챗봇에 쿼리 전송
return conversation_chain- Vector DB에 있는 데이터와 사용자 질문(프롬프트)를 함께 OpenAI 에 요청합니다.
- 받은 결과를 반환합니다.
4.4 server.py
import rag
from flask import Flask, jsonify, request
import streamlit as st
app = Flask("PDF_Test")
@app.route('/pdf', methods=['post'])
def uploadPDF():
data = request.get_json()
pdf_text = data["data"]
# 텍스트에서 청크 검색
text_chunks = rag.get_text_chunks(pdf_text)
# PDF 텍스트 저장을 위해 FAISS 벡터 저장소 만들기
vectorstore = rag.get_vectorstore(text_chunks)
# 대화 체인 만들기
st.session_state.conversation = rag.get_conversation_chain(vectorstore)
result = {
"result" : "success"
}
return jsonify(result)- PDF 를 받아 로직을 수행합니다.
- 청크 데이터 변환 후 Vector DB 생성 그리고 대화 체인(OpenAI 결과) 생성까지 기능을 수행합니다.
@app.route('/handbook', methods=['post'])
def sendData():
data = request.get_json()
query = data["data"]
if 'conversation' in st.session_state:
result = st.session_state.conversation({
"question": query,
"chat_history": st.session_state.get('chat_history', [])
})
result = result["answer"]
else:
result = "먼저 문서를 업로드해주세요~."
dic = {
"result" : "success",
"message" : result
}
return jsonify(dic)
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0', port=80)- 질문(프롬프트) 를 받아 OpenAI 결과를 반환합니다.
5. 결과

RAG 를 간단하게 구현을 해보았습니다.
개념 자체는 어렵다 생각했는데,
차근차근 이론 정리와 구현을 진행하다보니 어렵다 라는 생각보단 흥미롭다 라는 마음이 더 들었던 것 같습니다.
감사합니다.
참고
반응형
'기타👨🏻💻 > AI' 카테고리의 다른 글
| [AI] 이미지 웹 접근성 ( YOLO 모델 - 적용법과 간단 예제 ) (0) | 2025.02.28 |
|---|---|
| [AI] RAG 의 구성요소 2 ( Embedding ) (2) | 2024.09.04 |
| [AI] RAG 의 구성요소 1 ( Vector DB ) (0) | 2024.08.21 |
| [AI] RAG ( Retrieval Augmented Generation ) 의 기초 (0) | 2024.08.20 |
| [OCR] Google Vision Ai 적용 ( 이미지 분석 - Python ) (0) | 2024.03.20 |